NewSQL: Getest en Goedgekeurd
Vorige herfst schreven we onze eerste blog over de veelbelovende technologie NewSQL. Na een pauze en een periode met enkele testen, kunnen we nu bevestigen dat deze nieuwe databases effectief een positieve evolutie zijn.
Evolutie, geen Revolutie
Wat het database gebruik in de IT sector betreft, zien we nog steeds een ruime meerderheid voor traditionele databases. Leidende spelers zijn daarbij MySQL en PostgreSQL. Daarnaast weet ook de NoSQL database MongoDB aardig wat marktaandeel te veroveren. Van een revolutionaire opmars van NewSQL databases kan dus nog geen sprake zijn.
De reeds bestaande databases, zowel OldSQL als NoSQL, staan dan ook niet stil in hun evolutie, en groeien op verschillende vlakken naar elkaar toe. Enkele NoSQL producten bieden b.v. een beperkte ondersteuning voor SQL of SQL-achtige talen aan, en soms ook transacties. De traditionele relationele databases, op hun beurt, bieden allerlei manieren aan om horizontaal te gaan schalen en dus een gedistribueerd systeem op te zetten met een verhoogde beschikbaarheid. Men kan dus stellen dat de verschillende categorieën van databases dichter naar elkaar toegroeien.
Ook NewSQL kan men, zoals we reeds aanhaalden in de vorige blog, eigenlijk beschouwen als een soort naar elkaar toegroeien van beide andere categorieën. Zit er dan nog een effectieve vernieuwing in?
Het antwoord op die vraag situeert zich in een aantal producten die van nul af zijn opgebouwd met de problematiek van dit spanningsveld tussen consistentie en beschikbaarheid in gedachten, en die met een cloud native aanpak zijn ontworpen. Dit wil o.a. zeggen dat dit vanaf het begin een gedistribueerd ontwerp betreft. De basis architectuur en de opzet zijn aldus voldoende verschillend van de andere producten om er effectief het label "NewSQL" aan te hangen. Het resultaat zijn systemen die de gewenste eigenschappen combineren, zonder dat de installatie en het onderhoud nodeloos complex worden.
Om te zien hoe dit spanningsveld precies wordt aangepakt bij NewSQL, moeten we nog eens terugkomen op het befaamde CAP-theorema...
Van CAP naar PACELC
Het Cap theorema gaat vooral in op wat theoretisch niét kan (C, A én P tegelijk hebben). Het vertelt ons echter iets te weinig over wat men dan wel kan doen binnen de grenzen van wat theoretisch mogelijk is.
Wanneer alles redelijk normaal verloopt voor een gedistribueerd systeem, treden er geen netwerkpartities op. Op dat ogenblik kan men dus, in principe, volgens het CAP theorema, zorgen voor beschikbaarheid en consistentie tegelijkertijd. In de praktijk zal dit, indien alles naar wens verloopt en er geen al te zware load op het platform inwerkt, ook zo zijn. Zelfs de "eventual" consistency van NoSQL systemen zal dan slechts seconden zijn i.p.v. de langere tijd die men van "eventual" zou verwachten.
Nochtans moet men in dit geval ook nog keuzes maken... Het PACELC theorema, een uitbreiding op het CAP theorema, stelt namelijk dat men in afwezigheid van netwerkpartities, moet kiezen tussen latency en consistentie. NoSQL trekt hier duidelijk de kaart van latency: men aanvaardt onmiddellijk een request van een client, en rekent op de eventual consistency om alle nodes van het systeem op een redelijke tijd in orde te krijgen. NewSQL systemen daarentegen, kiezen consistentie: vooraleer de request wordt aanvaard, zorgt men ervoor dat voldoende nodes akkoord zijn en wanneer de request aanvaard is, zal dit ook zo zijn op de meeste nodes, zodat de consistentie gegarandeerd is over het gehele systeem. Deze fase van "akkoord bereiken" tussen de nodes zal de werking natuurlijk enigszins vertragen.
Consistency in CAP vs ACID
In de vorige blog kon je een iets langere uitleg lezen over Base, Acid en het CAP theorema. De "C" in zowel ACID als CAP staat voor Consistentie. Maar eigenlijk is dit een beetje verwarrend, want het is niet dezelfde consistentie die daarbij wordt bedoelt.
De ACID regels stammen reeds uit de jaren 1970, een tijd toen er nog nauwelijks sprake was van gedistribueerde systemen; het ging erom transacties te definiëren in een database wereld waar het gelijktijdig gebruik van een database door meerdere gebruikers nog in zijn kinderschoenen stond.
Consistentie in ACID stelt specifiek dat transacties de regels en restricties van de database moeten volgen (b.v. bepaalde constraints op data, maar eveneens zaken als triggers) en dat alle data die naar de database geschreven wordt, de database in een geldige toestand moet achterlaten. Dit geldt voor de gehele transactie. Geen enkele gebruiker mag de database in een toestand kunnen zien die ongeldig zou zijn, ook niet tijdens het uitvoeren van een transactie van een andere gebruiker.
Het CAP theorema werd pas geformuleerd in 2000 en geldt voor alle gedistribueerde systemen (niet enkel databases). Het doel was hier om scherp te stellen dat men keuzes zal moeten maken wanneer er een netwerkpartitie optreedt in een dergelijk systeem. Consistentie in CAP betekent dat alle replica's van hetzelfde gegeven ook dezelfde waarde zullen hebben overheen het hele systeem (en dus in alle nodes).
Het wordt extra interessant wanneer een systeem zowel de consistentie in ACID als die van CAP wil hebben. De ACID principes moeten dan over alle nodes heen tegelijk geldig zijn. Het spreekt voor zich dat dit niet eenvoudig is en, zeker in het geval van een netwerkpartitie, voor een specifieke aanpak zal zorgen.
De afkorting PACELC kan men dan via het volgende zinnetje opbouwen: Bij netwerkpartitie (P), moet men kiezen tussen beschikbaarheid (Availability) en Consistentie (C), en anders (Else), tussen latency (L) en consistentie (C).
Wanneer men over voldoende performantie beschikt, het systeem niet overbelast is, en er geen fouten optreden, zal men in de praktijk weinig merken van dit verschil tussen latentie en consistentie. Maar de specifieke garanties die worden geboden zijn echter wel heel belangrijk om weten wanneer men deze databases gaat gebruiken, vermits er altijd wel iets zal misgaan en er altijd wel een situatie kan optreden die het systeem te zwaar belast. Wil men ten allen tijde kunnen rekenen op consistentie, of op een zo hoog mogelijke beschikbaarheid en het zo weinig mogelijk missen en zo snel mogelijk afhandelen van requests? Een banktoepassing zal typisch het eerste willen, een webshop misschien eerder het tweede (en als er iets misgaat door inconsistentie in de data, maakt men dit achteraf wel goed met de klant).
In de praktijk is PACELC eigenlijk nuttiger dan CAP: indien men een systeem met hoge beschikbaarheid wil voorzien, moet men de facto aan duplicatie gaan doen, ook van data. Vanaf het moment dat data gedupliceerd wordt en verspreid over meerdere plaatsen, zal men een afweging moeten maken tussen hoe consistent men deze wil houden, en hoe snel men er mee wil kunnen werken.
![]()
Figuur 1: Het PACELC theorema
NewSQL in de Praktijk: Testresultaten
We testten 3 verschillende NewSQL producten tijdens deze studie: CockroachDB, TiDB en NuoDB. Het voornaamste doel van de test was om het gedrag bij het uitvallen van nodes te testen. De theorie stelt dat deze databases netjes blijven werken zolang een meerderheid van de nodes draait en deze elkaar kunnen zien. Op die manier kan er altijd een concensus worden bereikt betreffende transacties.
De test ging als volgt: eerst bouwen we een cluster van 3 nodes voor elk van deze producten; daar wordt eventueel nog een load balancer aan toegevoegd en ook voorzien we een machine die als client zal optreden. Daarna volgen er twee testen waarbij we de cluster vanaf de client machine bestoken met requests. We gebruiken hierbij de TPCC, dit is een gestandaardiseerde test voor OnLine Transaction Processing (OLTP) Databases, het soort databases die we typisch gebruiken als backend voor online toepassingen (de typische tegenhangers zijn databases die zich focussen op analytics). De TPCC is "test C" van de TPC (transaction processing performance council), en wordt vandaag beschouwd als de meest typische maatstaf.

Figuur 2: De logo's van CockroachDB, NuoDB en TiDB, de drie geteste producten
De twee testen verschillen in het volgende: de eerste keer gaat er niets mis: alle drie de nodes blijven netjes werken. Bij de tweede test-run zullen we echter na een tijdje één van de nodes geforceerd uitschakelen, alsof deze een stroompanne ondervindt. Deze node zal dan de helft van de testperiode uitgeschakeld blijven, om dan, nog tijdens de test, terug op te worden gestart.
De TPCC is in principe ook een performantietest, dus we kunnen eigenlijk ook zien hoeveel verkeer deze databases aankunnen. Dit was echter niet het hoofdopzet van de test en de resultaten kunnen hierdoor wat meer uit elkaar liggen. Ook spelen er bepaalde aspecten aan sommige NewSQL databases, die een impact hebben op de performantie, niet mee in onze test, vanwege de setup (verschillende nodes op virtuele machines, echter allen op dezelfde fysieke machine). Zo is de fysieke afstand tussen nodes belangrijk, en vaak is het ook van belang of de systeemklokken op de verschillende nodes niet teveel van elkaar afwijken (Voor Google Spanner rolt men hiertoe atoomklokken uit in de verschillende datacenters; er bestaan echter ook aanvaardbare goedkopere oplossingen).
Voor de drie geteste databases bekwamen we gelijkaardige resultaten. Alle drie bleven ze functioneel bij het falen van één van de drie nodes. Bij de laatste, NuoDB, vroeg dit echter extra configuratiewerk. Voor CockroachDB en TiDB was dit out-of-the-box ondersteund. Daarnaast werd de performantie weinig beïnvloed door het node-falen; er waren nauwelijks minder transacties in de testperiode (enkel voor NuoDB was het verschil iets groter). Wat wel opviel, was dat er enkele transacties een stuk langer duurden. We vermoeden dat deze transacties werden gedaan op het moment van het node-falen, waardoor ze werden benadeeld. Al bij al voldeden de drie geteste producten echter wel goed aan onze verwachtingen van beschikbaarheid. Hieronder een voorbeeld van de cijfers van de test van CockroachDB.
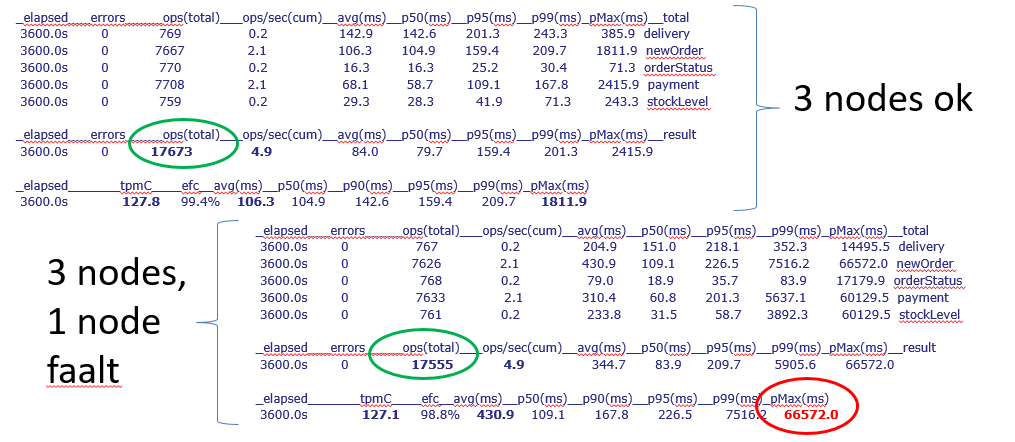
Figuur 3: Vergelijking van de testresultaten zonder en met node-falen voor CockroachDB. In groen is het totaal aantal transacties aangeduid. In rood de sterke vertraging van de traagste transactie bij node-falen.
Besluit
NewSQL databases beginnen vrij matuur te zijn. Ze zijn een prima keuze wanneer we voor een toepassing de voorkeur geven aan het gemak van data die consistent blijft en ondersteuning voor SQL, maar tegelijk toch een zeer goede beschikbaarheid willen. Het gedistribueerd karakter is ingebouwd in de technologie (ze zijn dus 'cloud native'), waardoor ze zich veel gemakkelijker dan de traditionele relationele databases laten uitrollen in clusters van meerdere evenwaardige nodes ('multi-master', i.t.t. de zgn. 'master-slave' setup), waarvan slechts een meerderheid operationeel moet blijven om het systeem beschikbaar te houden.
We kunnen echter ook enkele aandachtspunten aanduiden. Om een effectief systeem met hoge beschikbaarheid te hebben, moet men deze databases in principe uitrollen op verschillende locaties (eventueel zelfs in verschillende datacenters). Dit om ervoor te zorgen dat de kans zo klein mogelijk is dat verschillende nodes tegelijk falen. Tegelijk is het van belang dat deze nodes vlot met elkaar kunnen communiceren (en dat dit verkeer niet wordt onderschept) en op systemen draaien met een zo gelijk mogelijke systeemklok (voor sommige architecturen), anders wordt de performantie aangetast.
Deze aandachtspunten in beschouwing genomen, kunnen we echter besluiten dat NewSQL databases een goede keuze vormen wanneer men een cluster van redundante databases wil uitrollen voor verhoogde beschikbaarheid.
_________________________
Dit is een ingezonden bijdrage van Koen Vanderkimpen, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.