Digital mailroom : Vers une plus grande automatisation de la salle de courrier avec l’intelligence artificielle
Les administrations reçoivent quotidiennement une grande quantité de documents sous forme électronique ou par courrier. Ces documents sont ensuite envoyés vers les services adéquats et/ou vers un système de gestion électronique documentaire après extraction de métadonnées.
Ce processus de gestion électronique de documents commence par la numérisation c.-à-d. que les documents sont scannés et un OCR leur est appliqué s’il ne sont pas natifs numériques. Ensuite, les documents sont classifiés et indexés. L’indexation consiste à associer au document des données telles que le type de document, la date d’envoi, le numéro de référence afin de faciliter l’organisation et la recherche dans une base de données. Ils sont enfin stockés ou archivés.
La numérisation des documents entrants (scanning, OCR) est largement adoptée dans les administrations. Néanmoins, les étapes de classification, de routing et d’indexation se font encore souvent manuellement. Ils existent pourtant des techniques d’intelligence d’artificielle qui permettent de semi-automatiser ces étapes, ce sont ces techniques qui sont abordées ci-dessous. Tout ce processus automatique de traitement de documents, de la numérisation au stockage, porte le nom de digital mailroom ou salle de courrier numérique.
Les composants du digital mailroom
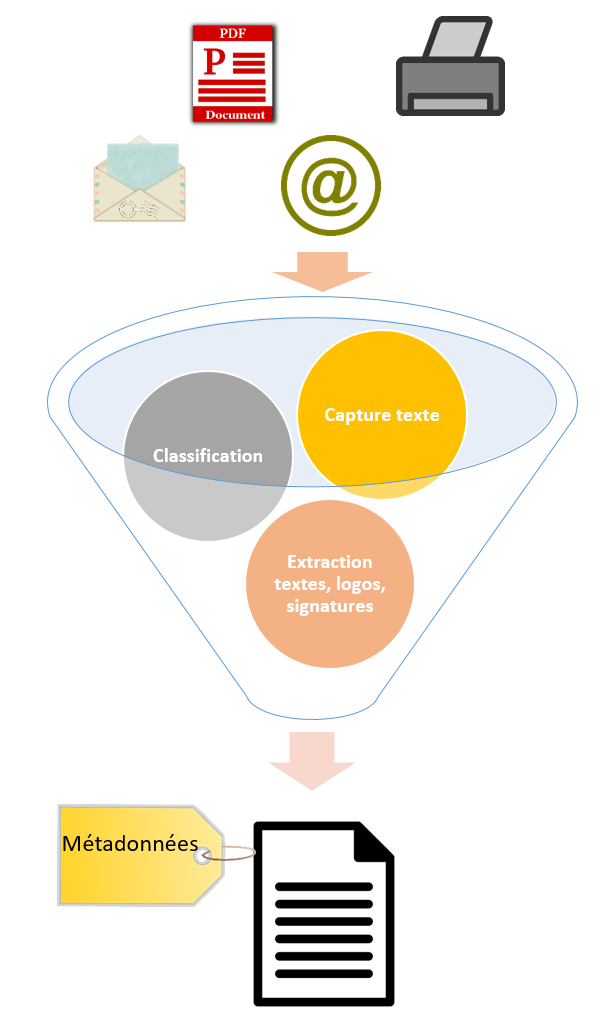
Enrichissement automatique des documents entrants avec des métadonnées
La plupart des systèmes de digital mailroom sont composés des éléments ci-dessous qui définissent le workflow appliqué aux documents entrants. Pour une plus grande automation dans le workflow, des techniques d’intelligence artificielle sont appliquées. Il s’agit du NLP (Natural Language Processing) pour la compréhension du contenu, de l’apprentissage automatique (machine learning) pour l’identification du type de document et enfin de la reconnaissance d’images et plus largement la vision par ordinateur (computer vision).
Une salle de courrier automatique inclut généralement :
- La capture de documents: les documents proviennent de différentes sources, emails, scanning, formulaires web…
- La capture de textes : utilisation de l’OCR pour extraire le texte complet du document, permet de convertir l’image issue du scanning en texte.
- La classification : la combinaison du NLP et de l’apprentissage automatique permet de déterminer automatiquement le type de document à partir du contenu ou de la structure du document. La classification peut être utilisée pour un routing appropriée du document vers le service interne adéquat.
- La capture d’informations : extraction de morceaux de texte (date, référence, nom, …) en appliquant le NER (Named Entity Recognition), l’extraction de logos et de signatures avec la reconnaissance d’images.
- La validation : le traitement automatique du document peut-être validé manuellement et corrigé si nécessaire.
Exemple d’application du digital mailroom: extraction des données de contacts de l’expéditeur
Pour un de nos clients nous avons réalisé un POC dont l’objectif était de capturer les données relatives à l’expéditeur du courrier : nom, fonction, numéro d’entreprise, numéro de téléphone et adresse électronique. Ceci est une application typique de NER intégrée à un système de gestion de documents entrants. Pour la réalisation de ce POC, nous avons utilisé des outils open source de NLP pour développer un modèle NER et nous avons pu faire les constatations suivantes :
Il faut prévoir une étape de validation
Les résultats obtenus pour le POC oscille entre 70% pour l’extraction de la fonction et plus de 90% pour l’extraction du numéro d’entreprise, il est donc utile de prévoir une étape de validation manuelle pour s’assurer que les informations extraites du document traité sont correctes. Cependant, certaines entités peuvent être validées automatiquement notamment le numéro d’entreprise.
Il vaut mieux utiliser des règles et méthodes simples là où c’est possible
Certaines entités comme le numéro d’entreprise peuvent être facilement extraites à l’aide d’une expression régulière. De plus, les documents entrants sont en grande partie des documents semi-structurés. Ce qui veut dire que l’expéditeur comme le destinataire sont toujours localisés à la même position. En ciblant cette zone du document à l’aide d’outils de vision par ordinateur, on peut extraire directement les données d’intérêt. On réserve alors l’utilisation des techniques de NLP combinées à l’apprentissage automatique aux problèmes où les règles sont complexes et/ou trop rigides pour accommoder tous les cas de figures.
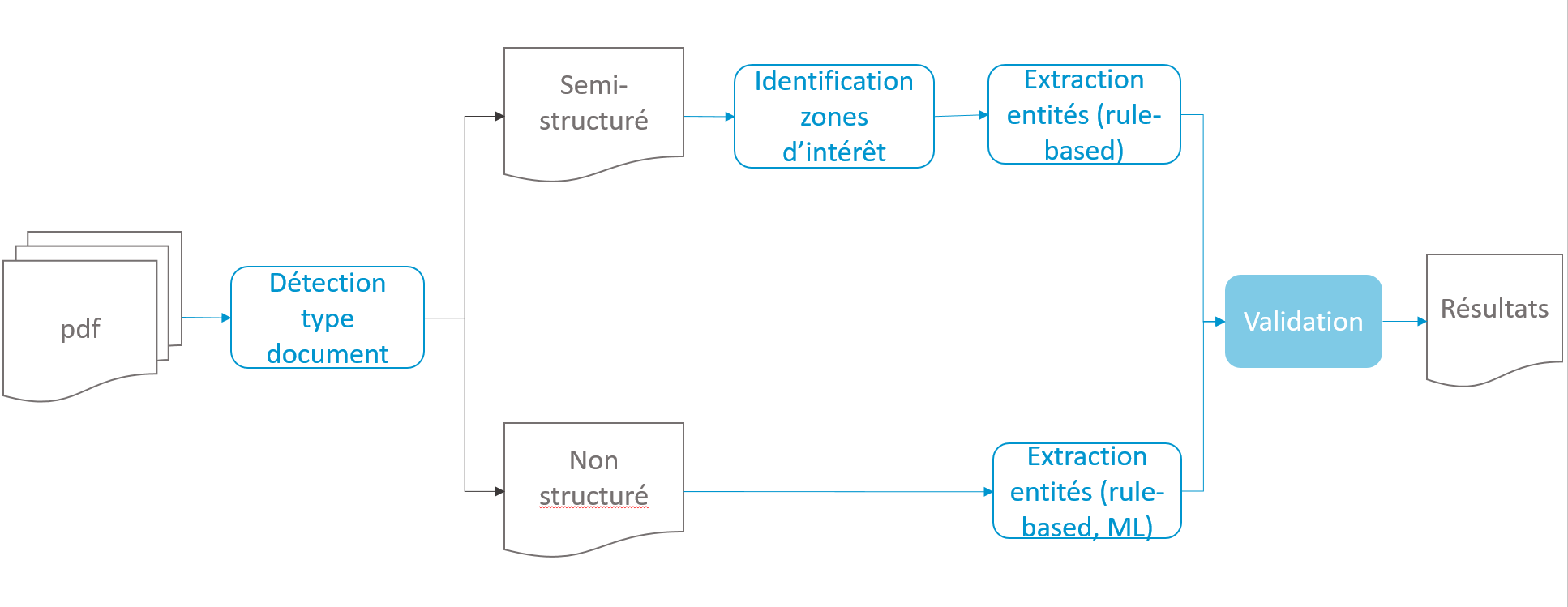
Approche pour l’extraction de données de l’expéditeur du document. Les documents semi-structurés et non structurés sont traités différemment.
Start small and grow
Avec un nombre limité de documents annotées pour le NER, on peut construire un système ayant des performances acceptables ; ceci peut servir de base pour démarrer. Dans le processus de validation manuelle, on corrige les erreurs du modèle. Ces corrections sont ensuite utilisées pour affiner le modèle qui, sur le long terme, fait de moins en moins d’erreurs. Ceci est aussi valable pour la classification de documents qui montrent déjà des résultats satisfaisants sur un test que nous avons mené sur un petit nombre de documents (30 documents par type).

Séquence de traitements automatiques du document. Les corrections apportées lors de l’étape de validation manuelle sont utilisées pour ré-entrainer les modèles de classification et d’extraction (apprentissage automatique).
Solutions sur mesure vs solutions commerciales
Il est possible de mettre en place une salle de courrier numérique (digital mailroom) en utilisant des outils open source, le POC décrit ci-dessus a été réalisé en majorité avec des outils de NLP et de machine learning open source. Ceci permet de développer une solution sur mesure et venant facilement s’intégrer à un processus de gestion de documents déjà existant.
Toutefois plusieurs fournisseurs de plateformes de numérisation de documents proposent aussi des solutions d’automatisation du traitement de documents plus ou moins élaborées, qui incluent le scanning, l’OCR, la classification, la capture d’informations et la validation. On peut citer comme exemple de ces plateformes IRIS (Canon) et Kofax. D’autres acteurs du domaine tels que Isis Papyrus, contract.fit, Iron Montain et docbyte sont aussi intéressants à considérer.
Ces plateformes présentes plusieurs avantages :
- Disponibilité de nombreuses fonctionnalités de traitement de texte
- Facilité de configuration par un utilisateur non IT et formé à l’utilisation de l’outil
- Utilisation de produits standards qui permettent une implémentation rapide et requièrent peu de développements
Il est toutefois important de noter que l’utilisation de plateformes commerciales ainsi que l’utilisation d’outils open source nécessitent d’annoter des données pour l’entraînement d’un modèle de classification ou de NER en adéquation avec le besoin du client.
En conclusion
La salle de courrier numérique (digital mailroom ) a une réelle plus-value dans les administrations étant donné le volume important de documents entrants qui y est traité. Ce traitement ne peut être totalement automatisé et nécessite une intervention manuelle, cependant le digital mailroom apporte une aide significative à l’agent et permet un traitement plus rapide des documents. On choisira une solution sur mesure ou une solution commerciale en fonction des besoins business, des coûts d’implémentation, des ressources disponibles pour le développement d’une solution et de l’infrastructure déjà en place.
_________________________
Ce post est une contribution individuelle de Katy Fokou, spécialisée en intelligence artificielle chez Smals Research. Cet article est écrit en son nom propre et n’impacte en rien le point de vue de Smals.