Betere zoekresultaten met vector databases
In de wereld van AI zijn vector databases een belangrijk hulpmiddel geworden. Ze stellen ons in staat om grote hoeveelheden ongestructureerde gegevens efficiënt op te slaan en te doorzoeken, wat cruciaal is voor veel toepassingen.
Vector embeddings
Vector databases beheren in essentie vectorgegevens. Dat zijn gegevens die worden weergegeven als een reeks getallen, of vectoren, die een punt in een hoog-dimensionale ruimte vertegenwoordigen. Het aantal getallen in een vector komt overeen met het aantal dimensies.
Het omzetten van gegevens naar vectoren gebeurt op basis van een embedding model, waarbij de betekenis (semantiek) ervan gecapteerd wordt. We spreken van vector embeddings. Zo zal de vector voor het woord “puppy” bijvoorbeeld dicht bij de vector voor “hond” liggen, en verder weg van “appel”.
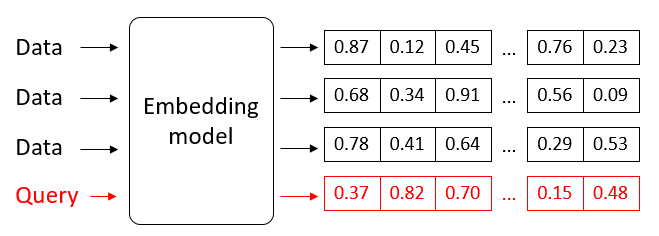
Het aanmaken van vector embeddings
Die vectoren worden geïndexeerd in een vector database opgeslagen, op zo een manier dat het opzoeken zo efficiënt mogelijk verloopt.
Similarity search
Het unieke aan vector databases is dat ze kunnen zoeken naar gelijkaardige gegevens ten opzichte van een inputvraag (query). We spreken van similarity search: in plaats van te zoeken naar exacte overeenkomsten kunnen vector databases zoeken naar gegevens die het meest vergelijkbaar zijn met een gegeven query.
Dat ‘vergelijkbaar zijn’ wordt berekend op basis van de afstand tussen vectoren in de zoekruimte: hoe kleiner de afstand tussen twee vectoren, hoe vergelijkbaarder ze zijn. Er bestaan verschillende functies om de afstand tussen twee vectoren te berekenen. De keuze kan afhangen van verschillende factoren: de gegevens, het gebruikte embedding model, en de afweging tussen accuraatheid en snelheid van uitvoering.

Afstandsfuncties voor het berekenen van de gelijkenis tussen vectoren
De meest voor de hand liggende manier om de dichtste vectoren te zoeken ten opzichte van een query vector is om de query vector exhaustief te vergelijken met alle vectoren in de databank (k-Nearest-Neighbors of kNN). Op die manier zijn we zeker dat we de k dichtste vectoren terugvinden. We krijgen in dit geval perfecte accuraatheid. De keerzijde is echter dat het een rekenintensieve methode is die niet schaalt.
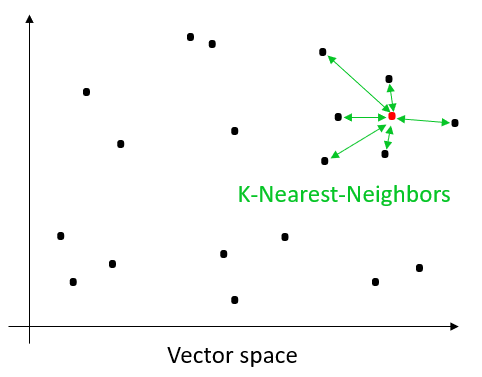
k-Nearest-Neighbors
Om performanter te kunnen zoeken in grote hoeveelheden gegevens zijn er approximatieve methodes waarbij er geen exhaustieve vergelijking is tussen de query en de vectoren in de databank (Approximative Nearest Neighbors of ANN). De meest gebruikte methode hiervoor is wellicht HNSW (Hierarchical Navigable Small World). Dat is een methode op basis van een hiërarchische graaf waarbij elke node een vector vertegenwoordigt en de links tussen de nodes de afstand ertussen aangeeft. Tijdens een zoekopdracht navigeert het algoritme efficiënt door de graaf, beginnend op hogere niveaus (waar de dichtheid van nodes lager is) en geleidelijk afdalend naar lagere niveaus om de dichtste buren te vinden.
Hybrid search
Hybrid search is een geavanceerde zoektechniek die de sterktes van vector search combineert met die van een klassieke keyword search. Keyword search (lexicaal zoeken) maakt gebruik van exacte overeenkomsten van trefwoorden in de tekst. Het is snel en eenvoudig, maar mist soms de contextuele nuances. Bij vector search (semantisch zoeken) wordt de betekenis in rekening gebracht. In de praktijk blijkt dat een combinatie van beide methodes betere resultaten oplevert dan elke methode afzonderlijk.
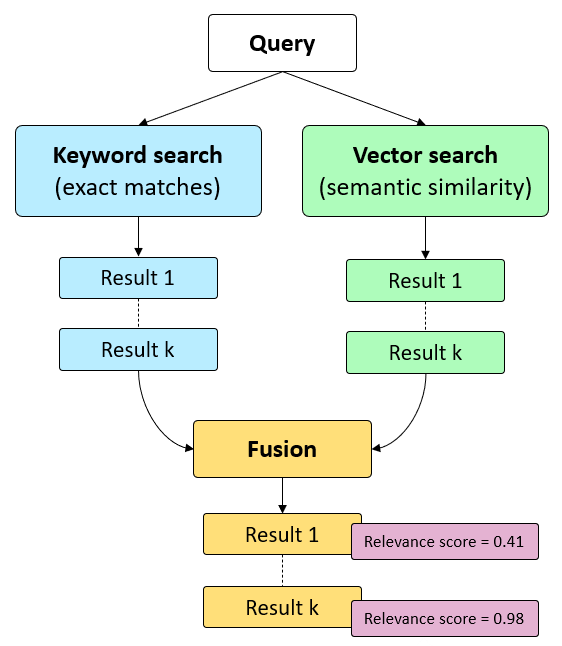
Hybrid search
Om de relevantie van de zoekresultaten nog te verbeteren kan er semantic ranking toegepast worden. Daarbij wordt een geavanceerd machine learning model gebruikt om de zoekresultaten te herschikken op basis van hun relevantie ten opzichte van de zoekopdracht. Dit is typisch een betalende feature of API waarbij je betaalt volgens verbruik. Een voorbeeld van zo’n dienst is Cohere Rerank.
Toepassingsgebieden
Vector databases kunnen voor een divers aantal toepassingen ingezet worden:
- Semantic search – Het mag ondertussen duidelijk zijn dat vector databases een belangrijke bijdrage kunnen leveren bij het verbeteren van de zoekresultaten op basis van semantische betekenis in plaats van enkel exacte matches.
- Question answering & RAG – Recent is er veel aandacht voor generatieve vraag-antwoordsystemen. Vector databases kunnen ingezet worden als retriever component in zo’n systeem. Men spreekt over Retrieval Augmented Generation (RAG). Dit is een aanpak waarbij een taalmodel antwoorden formuleert op basis van de meest relevante informatie uit een kennisbank.
- Aanbevelingen (recommender systemen) – Vector databases kunnen ook ingezet worden om informatie of producten aan te bevelen aan gebruikers, al dan niet op basis van hun historiek of voorkeuren.
- Multimodal similarity search – Bepaalde embedding modellen zijn in staat om vectoren aan te maken voor meerdere types van gegevens: niet enkel tekst, maar ook afbeeldingen, audio of video. Vector databases kunnen op die manier zoeken mogelijk maken naar gelijkaardige content, ongeacht of het gaat over tekst, afbeeldingen, audio of video.
Marktoverzicht
De initiële spelers op de markt voor vector databases, zoals Chroma, Milvus, Pinecone en Weaviate, boden voornamelijk purpose-built oplossingen aan. Pas later sprongen de meer gevestigde spelers op de kar. Zo bieden ElasticSearch en Postgresql (met de pgvector extensie) ook ondersteuning voor vector search. Uiteraard zijn ook de grote spelers vertegenwoordigd in het landschap: Microsoft biedt Azure AI Search, Google Vector AI Vector Search en Amazon Kendra.
Zo goed als alle oplossingen integreren met LLM orchestratie oplossingen zoals LangChain en LlamaIndex. Meer en meer bieden vector databases ook ingebouwde ondersteuning voor RAG, waarbij het aanmaken van embeddings en aanroepen van een taalmodel niet meer extern aan de vector database moet georchestreerd worden.
Ook vermeldenswaardig is Neo4j, dat naast graph search ook vector search ondersteunt en daarmee geschikt is voor cases met zowel gestructureerde als ongestructureerde gegevens.
Conclusie
Tot slot kunnen we stellen dat vector databases kunnen zorgen voor betere, relevantere zoekresultaten ten opzichte van een eenvoudige keyword search. Bij generative question answering toepassingen kunnen vector databases helpen een taalmodel antwoorden te laten formuleren op basis van de meest relevante informatie uit een kennisbank. Terwijl het niet evident is om grote taalmodellen op eigen infrastructuur te draaien, is dat bij vector database als retrieval component wel mogelijk, wat een gunstige factor kan zijn in het kader van gegevensbescherming.
Uit eigen ervaring merken we dat hybride search, een combinatie van vector search en lexical search, een quick win kan zijn om de zoekresultaten te verbeteren. Semantic ranking kan daarbovenop nog een extra boost geven aan de relevantie van de resultaten.
Dit is een ingezonden bijdrage van Bert Vanhalst, IT consultant bij Smals Research. Dit artikel werd geschreven in eigen naam en neemt geen standpunt in namens Smals.